I am going to add one DataNode to my existing cluster. This is going to be done in Ambari. My Hadoop ditribution is Hortonworks.
Work on the node
Adding new node to the cluster affects all the existing nodes – they should know about the new node and the new node should know about the existing nodes. In this case, I am using /etc/hosts to keep nodes “acquainted” with each other.
My only source of truth for /etc/hosts is on Ambari server. From there I run scripts that update the /etc/hosts file on other nodes.
- Open the file.
sudo vi /etc/hosts
- Add a new line to it and save the file. In Ubuntu, this takes immediate effect.
10.0.XXX.XX t-datanode02.domain t-datanode02
- Running the script to update the cluster.
As per now, I have one line per node in the script, as shown below. it is on my to-do list to create a loop that would read from original /etc/hosts and update the cluster.
So the following line is added to the existing lines in the script.cat /etc/hosts | ssh ubuntu@t-datanode02 -i /home/ubuntu/.ssh/key "sudo sh -c 'cat > /etc/hosts'";
- Updating the system on the new node
I tend to run this from Ambari. If multiple nodes are added, I run a script.ssh -i /home/ubuntu/.ssh/key ubuntu@t-datanode02 'sudo apt-get update -y && sudo apt-get upgrade -y'
- Adjusting maximum number of open files and processes.
Since this is a DataNode we are adding, number of open files and processes has to be adjusted.
Open the limits.conf file on the node.sudo vi /etc/security/limits.conf
- Add the following two lines at the end of the file
* – nofile 32768
* – nproc 65536 - Save the file, exit the CLI and log in again.
- The changes can be seen by typing the following command.
ulimit -a
Output is the following:
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 257202
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 32768
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 65536
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
Work from Ambari
- Log in to Ambari, click on Hosts and choose Add New Hosts from the Actions menu.

- In step Install Options, add the node that is soon to become a DataNode.
Hortonworks warns against using anything than FQDN as Target Hosts!
If multiple nodes are added in this step, they can be written one per line. If there is a numerical pattern in the names of the nodes , Pattern Expressions can be used.
Example nodes:
datanode01
datanode02
datanode03
Writing this in one line with Pattern Expressions:
datanode[01-03]
Worry not, Ambari will ask you to confirm the host names if you have used Pattern Expressions:
(This is a print screen from one of my earlier cluster installations)Private key has to be defined and SSH User Account is by default root, but that will not work. In my case, I am using Ubuntu, so the user is ubuntu.
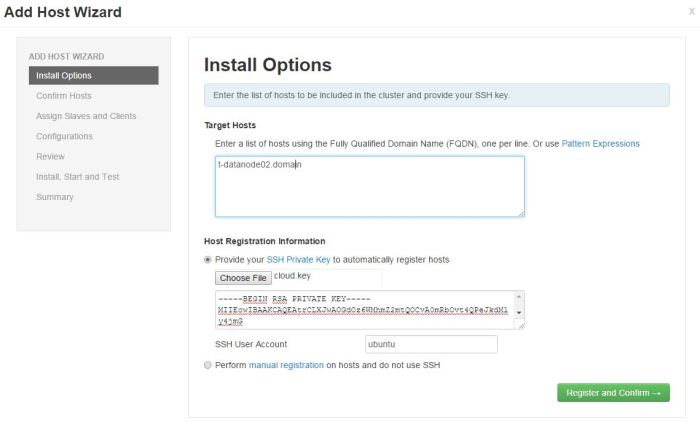
Now I can click Register and Confirm. - In the Confirm Hosts step, Ambari server connects to the new node using SSH, it registers the new node to the cluster and installs Ambari Agent in order to keep control over it.Registering phase:

New node has been registered successfully:
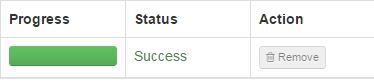
If anything else but this message is shown, click on the link to check the results. The list of checks performed is shown and everything should be in order before continuing (Earlier versions had a problem if ntpd or snappy was not installed/started, for example).

All good in the hood here so I can continue with the installation. - In step Assign Slaves and Clients I define my node to be a DataNode and has a NodeManager installed as well (if you are running Apache Storm, Supervisor is also an option).
 Click next.
Click next. - In step Configurations, there is not much to do, unless you operate with more than one Configuration Group.
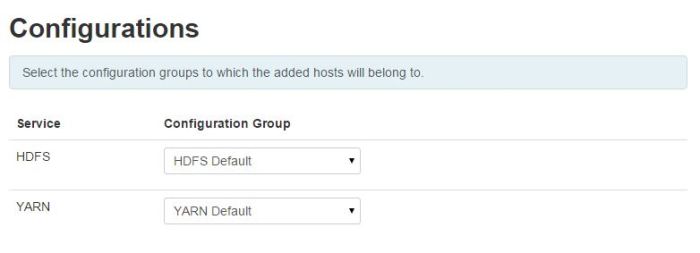 Click Next.
Click Next. - In step Review, one can just doublecheck if everything is as planned.
Click deploy if everything is as it should be. - Step Install, Start and Test is the last step. After everything is installed, new DataNode has joined the cluster.Here is how this should look like:
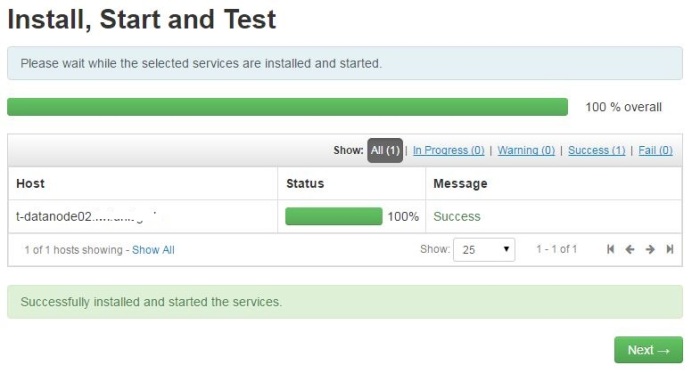 Click Next.
Click Next. - Final step – Summary – gives a status update.
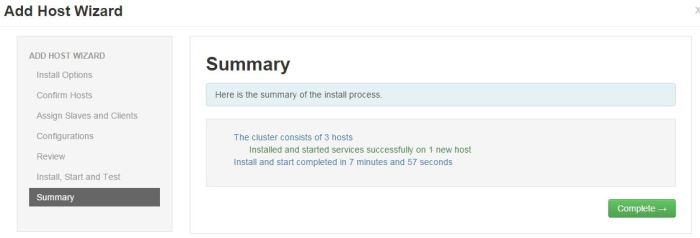 Click on Complete and list of installed Hosts will load.
Click on Complete and list of installed Hosts will load.