One way of adding new service to the HDP is by using a graphical interface Ambari. In this post, it is explained how the same is done using Ambari’s REST API. The service added in this post is Pig. Pig is not a “classical” service, rather a package, but from REST API’s point of view, it is a service.
The documentation on how to do this is dated April 21 2014. I have followed it and eventually made it work. The documentation can be found here.
The cluster
I am using AWS EC2 services, operating system is Centos7.
I have an Ambari server, version 2.6.2 and an HDP cluster version 2.6.5. This should work on other versions as well.
My cluster has one NameNode, on which Ambari is installed as well, and one DataNode. The services installed are the bare minimum – HDFS, YARN, MapReduce2, Zookeeper and Hive.
The goal
Install Pig client on the NameNode and on the DataNode.
Adding Pig to the cluster
Variables
export AMBARI_SERVER=PUBLIC_IP export MASTER_DNS=NAMENODE_PRIVATE_DNS export SLAVE_DNS=DATANODE_PRIVATE_DNS export CLUSTER_NAME=mincluster2
Create service on the Cluster
curl -u admin:admin -H "X-Requested-By:ambari" -i -X POST -d '{"ServiceInfo":{"service_name":"PIG"}}' 'http://'$AMBARI_SERVER':8080/api/v1/clusters/'$CLUSTER_NAME'/services'
Pig service is added to the list of services in Ambari.

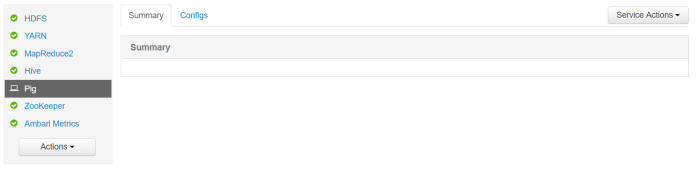
Check for service on the cluster
curl -k -u admin:admin -H "X-Requested-By:ambari" -i -X GET 'http://'$AMBARI_SERVER':8080/api/v1/clusters/'$CLUSTER_NAME'/services/PIG'

The service is registered on the cluster.
Add components to the service
curl -k -u admin:admin -H "X-Requested-By:ambari" -i -X POST -d '{"RequestInfo":{"context":"Install PIG"}, "Body":{"HostRoles":{"state":"INSTALLED"}}}' 'http://'$AMBARI_SERVER':8080/api/v1/clusters/'$CLUSTER_NAME'/services/PIG/components/PIG'
Running the curl command from previous step to check if the component is added returns the following:
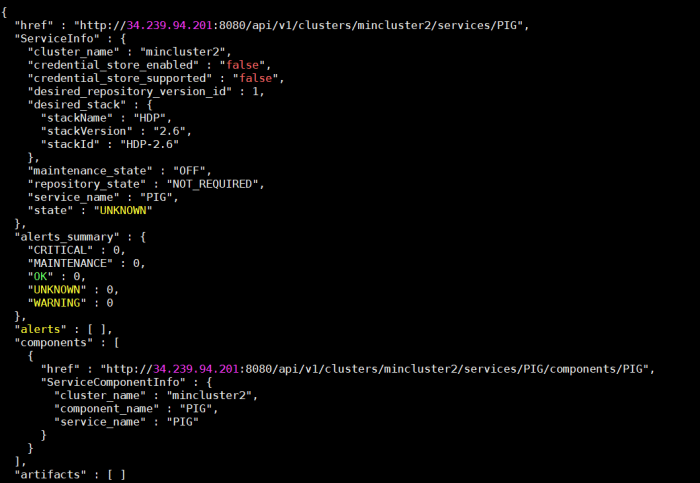
The component has been added according to the “components” element in the JSON output. The state of the service is still “UNKNOWN”.
Creating configuration is on the next page.