This post describes Nimbus and shows how its use with single Nimbus in Storm cluster, as well as Nimbus H/A.
I have a Hadoop cluster installed using Ambari. The distribution is Hortonworks. Storm installation with Ambari is described here
A basic example of Storm topology – writing to HDFS can be seen here. Might be smart to submit one topology first in orderto easier understand the terms like Bolt, Supervisor, Nimbus…
About Nimbus
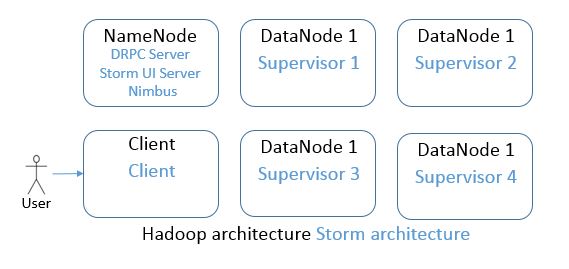
Nimbus is the master node in Storm cluster, it is the NameNode to your Hadoop.
Responsibilities:
- distributing code to Supervisors
- assigning tasks
- monitoring tasks
- restarting tasks when needed
Thrift
Thrift is a member of Apache family. It is a software framework (binary protocol) used for scalable cross language communication. Nimbus is a thrift service, and wide use of thrift in Storm allows users to define and submit topologies from any language.
Nimbus thrift API exposes all the information needed to monitor he Storm cluster.
ZooKeeper’s role
Nimbus stores all of its data in ZooKeeper. It is fail-fast (like Supervisor), so if Nimbus dies, the restart has no effect on the running tasks on the Supervisors.
Nimbus and Supervisors communicate through Zookeeper. This means that all data is stored in Zookeeper.
Submitting Topology in Storm Cluster
From the Storm client, the topology is submitted first to the Nimbus and Nimbus distributes it further to the Supervisors.
Single Nimbus in Storm Cluster
The only Nimbus in the Storm cluster is installed on the Hadoop NameNode.
If the Nimbus is not running, Storm UI (on port 8744) returns the following error message
java.lang.RuntimeException: Could not find leader nimbus from seed hosts ["nimbus-server1"]. Did you specify a valid list of nimbus hosts for config nimbus.seeds
Start Nimbus service from Ambari.
The Storm UI, under Nimbus Summary shows one host. It’s default port is 6627 and the status is “Leader”.
I am running one simple test Topology RandomWordsHdfsTopology and the log on the Supervisor executing the Bolt is showing me lines in the following manner:
2016-10-08 11:13:37.885 b.s.d.executor [INFO] Execute done TUPLE source: random-words-spout:5, stream: default, id: {}, [Spark] TASK: 4 DELTA:
2016-10-08 11:13:37.986 b.s.d.executor [INFO] Processing received message FOR 4 TUPLE: source: random-words-spout:5, stream: default, id: {}, [Hadoop]
2016-10-08 11:13:37.986 b.s.d.executor [INFO] BOLT ack TASK: 4 TIME: TUPLE: source: random-words-spout:5, stream: default, id: {}, [Hadoop]
2016-10-08 11:13:37.986 b.s.d.executor [INFO] Execute done TUPLE source: random-words-spout:5, stream: default, id: {}, [Hadoop] TASK: 4 DELTA:
2016-10-08 11:13:38.087 b.s.d.executor [INFO] Processing received message FOR 4 TUPLE: source: random-words-spout:5, stream: default, id: {}, [Kafka]
2016-10-08 11:13:38.088 b.s.d.executor [INFO] BOLT ack TASK: 4 TIME: TUPLE: source: random-words-spout:5, stream: default, id: {}, [Kafka]
2016-10-08 11:13:38.088 b.s.d.executor [INFO] Execute done TUPLE source: random-words-spout:5, stream: default, id: {}, [Kafka] TASK: 4 DELTA:
2016-10-08 11:13:38.188 b.s.d.executor [INFO] Processing received message FOR 4 TUPLE: source: random-words-spout:5, stream: default, id: {}, [Storm]
2016-10-08 11:13:38.189 b.s.d.executor [INFO] BOLT ack TASK: 4 TIME: 0 TUPLE: source: random-words-spout:5, stream: default, id: {}, [Storm]
And the random words are being written to a file in HDFS.
If the Nimbus shuts down, Zookeeper and Supervisor continue running the Topology. In this case, the log file on the Supervisor keeps logging random words and the file in HDFS continues to be appended. The Storm UI shows the error message posted above and running
storm list
from the Storm client machine returns the same error message.
Starting the Nimbus again and looking at the $STORM_LOGS/nimbus.log on nimbus-server1 teaches us how Nimbus reacts upon restart.
Some lines taken from the log file:
b.s.zookeeper [INFO] nimbus-server1 gained leadership, checking if it has all the topology code locally.
b.s.zookeeper [INFO] active-topology-ids [RandomWordsHdfsTopology-1-1475917797] local-topology-ids [RandomWordsHdfsTopology-1-1475917797] diff-topology []
b.s.zookeeper [INFO] Accepting leadership, all active topology found localy.
b.s.d.nimbus [INFO] Starting Nimbus server...
...
b.s.zookeeper [INFO] Accepting leadership, all active topology found localy.
With other words, the active Topology did not suffer from Nimbus downtime. With Nimbus down, nonew Topologies can be submitted and existing ones cannot be manipulated.
Multiple Nimbus in Storm Cluster
Adding another Nimbus for Nimbus High Availability is simple in Ambari.
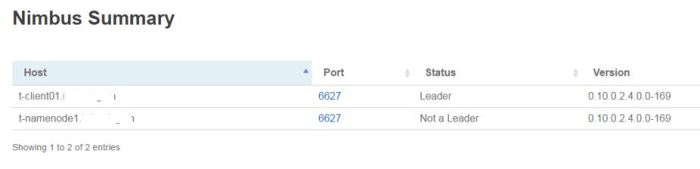
The second Nimbus is added on the Client node of the cluster. After it is added and the Storm service restarted, the Storm UI, under Nimbus Summary shows two Nimbus hosts one being Leader and one having status “Not a Leader”.
The client-server2, which has “Not a Leader” Nimbus reveals the following lines in the nimbus.log file:
...
b.s.d.nimbus [INFO] not a leader, skipping cleanup-corrupt-topologies
b.s.d.nimbus [INFO] Starting Nimbus server...
b.s.d.nimbus [INFO] not a leader, skipping assignments
b.s.d.nimbus [INFO] not a leader, skipping cleanup
b.s.d.nimbus [INFO] not a leader skipping , credential renweal.
...
b.s.d.nimbus [INFO] missing topology RandomWordsHdfsTopology-1-1475917797 has state on zookeeper but doesn't have a local dir on this host.
...
b.s.d.nimbus [INFO] trying to download missing topology code from NimbusInfo{host='nimbus-server1', port=6627, isLeader=false}
The “Not a Leader” Nimbus is now updated with the Storm CLuster and its topologies. Now the leader Nimbus is stopped:
b.s.zookeeper [INFO] client-server2 gained leadership, checking if it has all the topology code locally.
b.s.zookeeper [INFO] active-topology-ids [RandomWordsHdfsTopology-1-1475917797] local-topology-ids [RandomWordsHdfsTopology-1-1475917797] diff-topology []
b.s.zookeeper [INFO] Accepting leadership, all active topology found localy.
The Nimbus on client-server2 takes over as the Leader and Nimbus on the nimbus-server1 has status “Offline”.
When multiple Nimbus services are up and running, the “Leader” status is being switched between them. Roughly, this goes on every couple of minutes.
Nimbus has a vital role in the Storm Cluster and it is naive to think as long as Topology is running, I do not need Nimbus.