
About Storm
Storm is a free and open source distributed real-time computation system.
Storm cluster follows master-slave model and Zookeeper is used for coordination. All data is stored in ZooKeeper.
The basic unit of data processed by Storm is tuple. Tuple consists of predefined list of fields.
Storm cluster on Hadoop
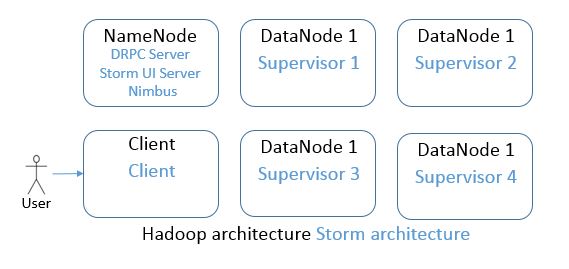
The following graphic explains the architecture one ends up with after following this post. In black text, the Hadoop nodes are shown, in blue text, Storm nodes are shown.
6 nodes in the cluster. One is dedicated NameNode, one is Client and four are DataNodes.
6 nodes in the cluster. One is dedicated to Nimbus, DRPC Server and Storm UI Server, one is Storm Client and four are Supervisors.
Ports
Make sure you open the following ports:
Node where Nimbus (master) is (are) installed: 2181, 6627.
Nodes where Supervisors (slaves) will be installed: 6700, 6701 (and so on, depending on the number of workers per supervisor).
Default Storm UI Server port is 8744, open the port on the node where this service is installed.
Adding Service in Ambari
Add Service Service
Select the Storm service:

Click Next.
Assign Masters

Nimbus is the master, responsible for distributing code across worker nodes, assigning tasks, monitoring tasks for any failures and restarting them when required. Nimbus and slaves communicate through ZooKeeper.
Click Next.
Assign Slaves and Clients
Check Supervisors on all datanodes you wish to use as supervisors.
Supervisor nodes are worker nodes.
Click Next.
Customize Services
Define ports on supervisors. One port per worker. By defining the ports one basically defines how many workers per supervisor will run.

Leave the default ports for now.
Review
If everything is ok, Click Deploy.
Install, Start, Test
When the installation is complete, click Next.
Restart Required
Restart HDFS, MapReduce2, YARN and Hive. Ambari reminds you about that. The Storm Web UI should now be available on the server where Storm UI Server is installed and on port 8874.
Adding Nimbus
Adding Nimbus is quite straightforward.
In Ambari, click on service Storm.
On the right side, there is a menu Service Actions. Click on it and select Add Nimbus.
Choose the host to add Nimbus component. In this case, I am adding a Nimbus to mz client node in the cluster.
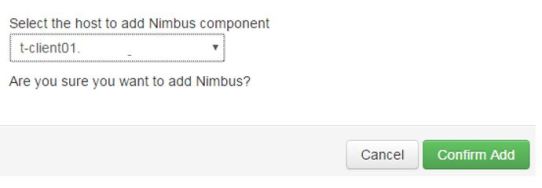
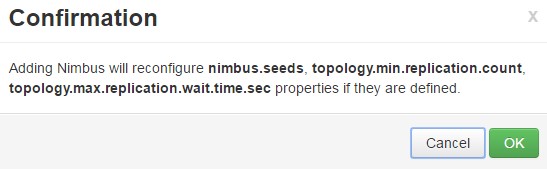
Click OK on the confirmation box
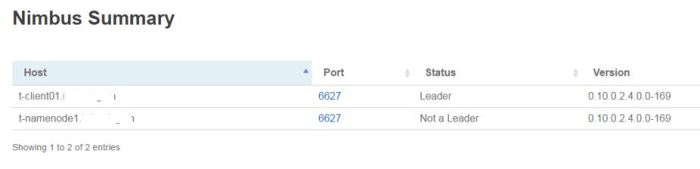
The Nimbus is now installed. On two instances – client and NameNode.
Restart of the Storm service is needed to make the second Nimbus part of services. The newly added Nimbus has status “Not a Leader”, while the primary Nimbus has status “Leader”.
Storm client? Yes, with a small workaround
Since I am not implementing High Availability for Storm, there is no need for two Nimbuses. The reason I added one Nimbus to the client is to get Storm client on it.
So if I remove the Nimbus from the client node, the Storm packages remain and potential Storm users can access the Storm service from the client – just like any other services in the cluster.
I can remove the Nimbus from the client just like any other service in Ambari – I stop the service and delete it.
The storm.yaml on the Client will be used when uploading the topologies and at the moment, the property nimbus.seeds has 2 properties – client FQDN and NameNode FQDN – each for one Nimbus location. The upload will still work, but if the non-existing Nimbus server is checked first, it will return an error and look for the next Nimbus server on the list.
Overview over Storm in Ambari
The summary in Ambari reveals the following picture:

One Nimbus (master), 4 Supervisors (slaves) and 8 slots (4 Supervisors x 2 ports, one for each worker on each Supervisor).
Learning about Storm
I have taken the Udacity course Real-Time Analytics with Apache Storm by Twitter. Great course! Very well explained and besides learning about Storm, I also became familiar with in-memory database Redis.
My topology
I have a test topology running which takes in tweets and “bolts” them in the following storages:
- pushes raw JSON files directly to HDFS
- creates tuples (user-tweet), does data cleansing and pushes them in Redis
- pushes information about user, tweet, date to MySql
I keep upgrading and improving my Topology.
Further work
- Working with Trident
- Checking how Spark Streaming can compete with Storm
- Testing Apache Samza to find out why LinkedIn was not happy with Storm and decided to develop Samza
Now we can start playing with Storm! Here is an example of Storm topology that takes random words and pushes them into HDFS.
