
The previous post mentions Consul and git2consul which are storing the parameters and fetching data from GitHub to Consul. It is only fair to gain more in-depth knowledge about them.
Consul is a product of a company called HashiCorp and together with Terraform (and other I do not mention yet) forms a group of tools called HashiStack. Consul is a tool for service configuration we build with our scripts. The scripts are the general presentation of the to-be state, while the configuration in Consul personalizes the infrastructure we plan to build (provision).
Service git2consul “mirrors the contents of a git repository into Consul KVs”. With other words, the service reads a git repository and creates/updates key-value pairs in Consul.
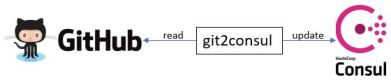
High level presentation of git2consul and Consul cooperation – git2consul periodically reads from a given GitHub repository and updates the Consul server
The previous post describes how local Consul server is started when the Docker container is ran. Local Consul is acceptable for testing purposes, it is possible and advised to build a distributed Consul service which offers High Availability (avoids single point of failure).
Configuration in YAML
A dedicated GitHub repository for the configuration parameters for my IaC projects can be found here. One YAML file for one project. For example configuration for the VPC architecture defines the services built in VPC that serve as the foundation for clusters built on top, for example configurations (I write in plural since there are/can be more than one) for a Spark cluster.
The git2consul configuration file inside the Docker container holds parameters, among them also the URL to the GitHub repository that serves as configuration repository. The file I am using for my git2consul service is here. It is copied over in the container when the image is created.
The following graphic show the same configuration parameters in three ways. First image is YAML file as seen in GitHub (I use Atom for development), second picture shows the same parameters as seen using a consul API from the command line in the Docker and the third picture shows a print screen of the same parameters in Consul web server.
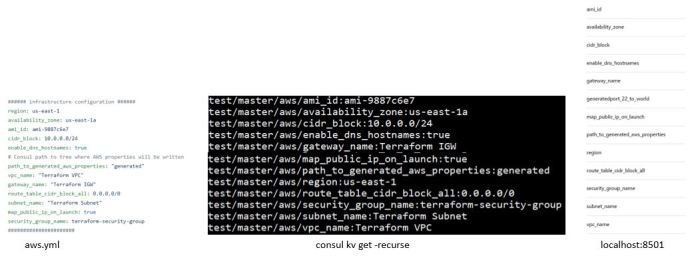
Three views of same key-value pairs – GitHub, command line and Consul web server
Another example, this one of Machine Learning in Spark shows how two different machine learning projects are configured in spark.yml. The prerequisite to run either of this is the VPC infrastructure and the input files (key spark_job_args). This example show that the scripts used to build the Spark cluster are untouched while the configuration in Consul personalizes the use case. If a new Spark job should be run, it is best to copy an existing block of key-value pairs and change to fit the needs.
A more complex example is the hdp.yml file which holds key-value pairs for five different Hadoop clusters. All can be provisioned using the same Terraform and Ansible scripts.
Writing to Consul at runtime
As mentioned a couple of times, the VPC in AWS is prerequisite and the established VPC is where all the following solutions are built in. This requires saving some values of the VPC so that they can be picked up at the provisioning of the next solution. These values are saved in Consul and are NOT pushed to GitHub – git2consul works one way only.
Once the VPC is provisioned, Terraform writes to Consul in a path defined by the user. In my example, everything starting with generated under the aws is coming from Consul.
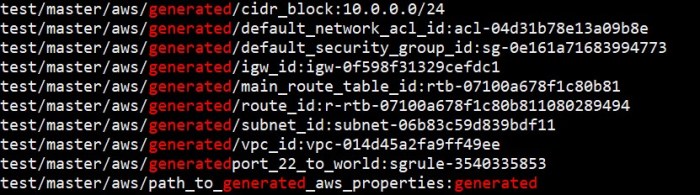
Key-value pairs generated when VPC is provisioned. Observe the last line – it specifies the name which should be used to gather all generated key-value pairs under.
These values are further picked up in other Terraform scripts so that the infrastructure that is being build knows where to fit in. I mentioned Spark and Hadoop earlier – the instances launched in AWS need the generated key-value pairs for successful launch.

One thought on “Service configuration tools and files”