
In earlier posts, I describe how to build and configure Zeppelin 0.6.0 and Zeppelin-With-R. Here is how the interpreters are configured.
The following interpreters are mentioned in this post:
- Spark
- Hive
Spark interpreter configuration in this post has been tested and works on the following Apache Spark versions:
- 1.5.0
- 1.5.2
- 1.6.0
Basic Spark
Once the page loads, click on Interpreter tab.
Edit spark interpreter
Change the master parameter
master yarn-client
Add 2 properties
spark.driver.extraJavaOptions -Dhdp.version=2.3.4.0-3485 spark.yarn.am.extraJavaOptions -Dhdp.version=2.3.4.0-3485
The bare minimum is now reached. How to get control over the Spark ports is described here.
Hive
Edit default.url parameter under Hive interpreter
default.url jdbc:hive2://hiveserver2:10000
Add 3 properties to hive interpreter
hive.hiveserver2.password hive hive.hiveserver2.url jdbc:hive2://hiveserver2:10000 hive.hiveserver2.user hive
Testing Zeppelin
Create new Notebook and test it.
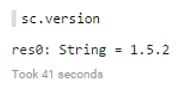
Scala
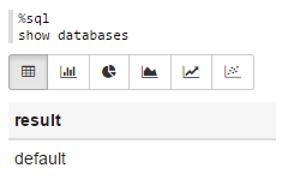
SparkSQL
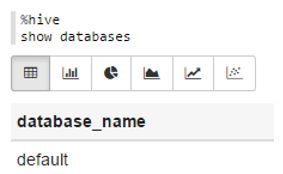
Hive
PySpark


Hi! thank you so much. Finally I got rid of those Java Socket errors while trying to run Spark.
Now I have this new error which is a bit shorter but I couldn’t really find a way to debug it.
Below are some few lines from my log.
INFO [2016-07-18 12:28:56,815] ({pool-2-thread-2} Logging.scala[logInfo]:59) – Successfully started service ‘HTTP class server’ on port 38005.
ERROR [2016-07-18 12:28:59,695] ({pool-2-thread-2} Utils.java[instantiateClass]:74) – SparkJLineCompletion
java.lang.ClassNotFoundException: SparkJLineCompletion
LikeLike