
Notes from Big Data: Principles and best practices of scalable realtime data systems, which is a book about how to implement Lambda architecture using Big Data technologies.
1. A new paradigm for Big Data
1.1 Scaling a traditional database
When you evolve the application, you will run into problems with scalability and complexity.
Steps from traditional database to Big Data architecture:
- Single increment is wasteful; it is more efficient to batch many increments in a single request. This is done by using queues – 100 events from the queue are read and processed.
- Database gets overloaded, one worker cannot keep up – you parallelize the updates. You try to scale a relational database – multiple servers are used and spreading the table across all the servers – each server will have a subset of the data, aka horizontal partitioning or sharding.
- At one point, a bug sneaks in the production.
More time is spent on dealing with reading and writing data, and less on building new features for customers.
1.2 How will Big Data techniques help?
The databases and systems for Big Data are meant for distributed work. Sharding and replication are handled for you. For scaling, you just add nodes and the systems rebalances automatically.
Making data immutable is another key feature.
Scalable data systems are available now. Large-scale computation system like Hadoop and databases like Cassandra and MongoDB. They can handle very large amounts of data, but with trade-offs.
Hadoop can parallelize large-scale batch computations on very large amounts of data, but with high latency.
NoSQL databases offer you scalability, but with a more limited data model than what SQL has to offer.
These tools are not a universal problem solver. However, with the best use in a combination with one another, you can build scalable systems with human-fault tolerance and minimum complexity. The Lambda architecture offers that.
1.3 Desired properties of a Big Data system
A Big Data system must perform well and be resource-efficient.
1.3.1 Robustness and fault tolerance
Systems need to behave correctly despite machines going down randomly. The systems must be human-fault tolerant.
1.3.2 Low latency reads and updates
Big Data systems have to deliver low latency updates when needed.
1.3.3 Scalability
Scalability is the ability to maintain performance in case of increasing data by adding resources to the system.
1.3.4 Generalization
A general system can support a wide range of applications. Lambda architecture generalizes by basing on functions of all data; whether financial systems, social media analytics, etc.
1.3.5 Extensibility
Functionality is added with minimum development cost.
1.3.6 Ad hoc queries
It is important to be able to do ad hoc queries. Every dataset has some unexpected value in it.
1.3.7 Minimal maintenance
Keep it simple. The more complex a system, the more likely something will go wrong. Big Data tools with little implementation complexity should be prioritized. In Lambda architecture, the complexity is pushed out of the core components.
1.3.8 Debuggability
A Big Data system must provide the information necessary to debug the system when needed. The debuggability in Lambda architecture is accomplished in the batch layer by using recomputation algorithms when possible.
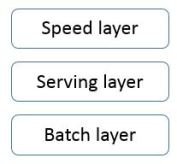
1.4 Lambda architecture
There is no single tool to provide a complete solution. A variety of tools and techniques is needed to build a complete Big Data system.
The main idea is to build a Big Data system as a series of layers. Each layer build upon functionality provided by the layer beneath it.
Everything starts from the following equation:
query = function(all data)
Ideally, you could run the functions on the fly to get the results. This could be too expensive and too resource consuming. Imagine reading petabytes of data every time one simple query is executed.
The best alternative is to precompute the query function. The precomputed query function is the batch view. User’ query fetches data from the precomputed view. The batch view is indexed so that it can be accessed with random reads. The above equation would now look like this:
batch view = function(all data)
query = function(batch view)
Creating the batch view is clearly a high-latency operation. By the time it finishes, new data will be available that is not presented in the batch views.
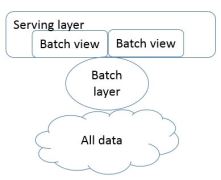
1.4.1 Batch layer
The batch layer stores the master copy of the dataset and precomputes the batch views on it.
The batch layer needs to be able to do two things:
- store immutable, growing master dataset
- compute random functions on that dataset (ad hos queries)
The batch layer is simple to use. Batch computations are written like single-threaded programs and the parallelism comes free.
The batch layer scales by adding new machines.
1.4.2 Serving layer
The serving layer is a specialized distributed database that loads in a batch view and makes it possible to do random reads on.
A serving layer database supports batch updates and random reads. It does not need to support random writes. Random writes cause most of the complexity in databases.
The serving layer uses replication in case servers go down. Serving layer is also easily scalable.
1.4.3 Speed layer
The speed layer ensures that new data is represented in query functions. It looks only at recent, new data.
It updates the real-time views as it receives new data. It does not recompute the views from scratch like the batch layer.
real-time view = function(real-time data, new data)
The Lambda architecture in three equations:
batch view = function(all data)
real-time view = function(real-time data, new data)
query = function(batch view, real-time view)
Results from queries come from merging results together from batch and real-time views.
One data makes it from batch layer into serving layer; the corresponding results in the real-time views are no longer needed.
The speed layer is far more complex than the batch and serving layer. This is called complexity isolation – complexity is pushed into a layer who delivers temporary results.
On the batch layer, the exact algorithm is used, while on the speed layer, an approximate algorithm is used.
The batch layer constantly overrides the speed layer, so the approximations are corrected – the systems shows eventual accuracy.
1.5 Recent trends in technology
1.5.1 CPUs are not getting faster
We are hitting limit of how fast a single CPU can go. This means that if you want to scale more data, you must parallelize your computation.
Vertical scaling – scaling by buying a better machine.
Horizontal scaling – adding more machines.
1.5.2 Elastic clouds
Rise of elastic clouds – Infrastructure as a Service. User can increase or decrease the size of the cluster instantaneously.
1.5.3 Vibrant open source ecosystem for Big Data
Five categories of open source projects:
- Batch computation systems
High throughput, high latency systems. Example is Hadoop.
- Serialization frameworks
Provide tools and libraries for using objects between languages. They serialize an object into a byte array from any language and then deserialize that byte array into an object in any language. Examples are Thrift, Avro, and Protocol Buffers.
- Random access NoSQL databases
They lack full expressiveness of SQL and specialize on certain operations. They are meant to be used for specific purposes. They are not meant to be used for data warehousing. Examples are Cassandra, HBase and MongoDB.
- Messaging/queuing systems
They provide a way to send and consume messages between processes in a fault-tolerant and asynchronous way. They are key for doing real-time processing. Example is Kafka.
- Realtime computation system
They are high throughput, low latency and stream-processing systems. They cannot do computations like batch-processing systems can, but they process messages extremely quickly. Example is Storm.
