
2. Data model for Big Data
2.1 The properties of data
The core of the Lambda architecture is the master dataset. It is the only part of the architecture, which should be guarded from corruption.
There are two components to the master dataset:
- data model
- how master dataset is physically stored
Definitions of the terms:
- information – general collection of information relevant to the system
- data – information that cannot be derived from anything else
- queries – questions to ask the data
- views – information derived from the base data
One person’s data can be another’s view.
2.1.1 Data is raw
It is best to store the rawest data you can obtain. This is important because you might have some question to ask your data in the future that you cannot ask now.
Unstructured data is rawer than normalized data. When deciding what raw data to store, there is a grey area between parsing and semantic normalization. Semantic normalization is the process of transforming free-form information into structured form. The semantic normalization algorithm would try to match the input with a known value.
It is better to store data in unstructured form, because the semantic normalization algorithm might improve over time.
2.1.2 Data is immutable
Relational databases offer operation update. With Big Data systems, immutability is the key. Data is not updated or deleted, only added. Two advantages derive from it:
- human-fault tolerance – no data is lost if a human failure is present
- simplicity – immutable data model offers only append operation
One trade-off for immutable approach is that it uses more storage.
2.2 The fact-based model for representing data
Data is the set of information that cannot be derived from anything else.
In the fact-based model, you represent data as fundamental units – facts. Facts are atomic because they cannot be divided into further into meaningful components. Facts are also timestamped, which makes them eternally true.
Facts should also be uniquely identifiable – in case of two identical data coming in at the same time (f. ex. pageview from same IP address at the same time), nonce can be added. Nonce is a 64-bit randomly generated number.
Fact-based model:
- stores your raw data as atomic facts.
- facts are immutable and eternally true
- each fact is identifiable
Benefits of the fact-based model:
- queryable at any time in history
- human-fault tolerant
- handles partial information
- has advantages of normalized (batch layer) and denormalized (serving layer) forms. These are mutually exclusive, so a choice between query efficiency and data consistency has to be made.
Having information stored in multiple locations increases the risk of it becoming inconsistent (list of values type of solution is in place here). This removes the risk of inconsistency, but a join is needed to answer queries – potentially expensive operation.
In the Lambda architecture, the master dataset is fully normalized. The batch views are like denormalized tables and are defined as functions on the master dataset.
2.3 Graph schemas
Graph schemas capture the structure of a dataset stored using the fact-based model.
2.3.1 Elements of a graph schema
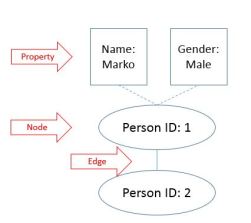
Graph schema has three components:
- nodes – entities in the system
- edges – relationships between nodes
- properties – information about entities
2.3.2 The need for an enforceable schema
Information is now stored as facts, graph schema describes the types of facts. What is missing is in what format to store the facts.
One option is to use semistructured text format like JSON. This provides simplicity and flexibility. The challenge might appear when valid JSON but with inconsistent format or missing data appears.
In order to guarantee consistent format an enforceable schema is an alternative. It guarantees all required fields are present and ensure all values are of expected type. This can be implement using serialization framework. Serialization network provides a language-neutral way to define the nodes, edges and properties of the schema.
One of the beauties of the fact-based model and graph schemas is that they can evolve as different types of data become available.
