
The program runs small jobs a number of times and checks whether small jobs are responsive. It is a complementary benchmark test to Terasoft.
What this benchmark test does is it creates a folder MRBench on HDFS in /benchmarks and generates an input file in the input folder. This input file holds one string per line. After the input file is created, it is split into the output folders with amount of files matching the value of parameter reduces.
This job can be run many times, depending on parameter numRuns value. The parameters are explained further in the post.
The jar file needed for MRbench, in Hortonworks distribution, can be found under /usr/hdp/{hdp-version}/hadoop-mapreduce.
The cluster used for running tests for this post has HDP version 2.3.4.0-3485. One of my other clusters, running HDP 2.4, has version 2.4.0.0-169, for example.
Running the following jar file
yarn jar /usr/hdp/2.3.4.0-3485/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-tests.jar mrbench --help
returns all the arguments available
MRBenchmark.0.0.2 Usage: mrbench [-baseDir <base DFS path for output/input, default is /benchmarks/MRBench>] [-jar <local path to job jar file containing Mapper and Reducer implementations, default is current jar file>] [-numRuns <number of times to run the job, default is 1>] [-maps <number of maps for each run, default is 2>] [-reduces <number of reduces for each run, default is 1>] [-inputLines <number of input lines to generate, default is 1>] [-inputType <type of input to generate, one of ascending (default), descending, random>] [-verbose]
reduces defines number of reduce jobs which is also seen in number of output files (input data is split into number of files equal to reduces value).
numRuns defines number of times the test is going to be run. Each job starts with the following info:
INFO mapred.MRBench: Running job 0
The counter starts at 0 and ends with numRuns – 1.
inputLines defines number of lines generated. These lines hold one number per line. If inputLines is 100, numbers from 000 to 099 are generated. In what order are they generated is defined by inputType.
inputType defines sort order of the numbers generated.
For example, if we define inputLines to be 1000 and inputType ascending (default), this will generate numbers from 0000 to 0999 in the input file, one value per line.
Value descending for inputType is going to sort them from 0999 to 0000 in the input file.
Value random is going to generate random numbers with no sorting. And trust me, they will be random.
Example:
6493553352002875669
-6076474133462114203
-4219424128611728137
3147428516996533652
8833283876026349807
-6231574853220588520
4464414501313572651
4107251190398906611
7209395140850842640
-8963297226854656877
The program can be run with no attributes as well, as Test 1 shows.
Test 1: No arguments
The default values of the arguments are the following:
| Argument | Default value |
| numRuns | 1 |
| maps | 2 |
| reduces | 1 |
| inputLines | 1 |
| inputType | ascending |
yarn jar /usr/hdp/2.3.4.0-3485/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-tests.jar mrbench
Output (with my comments):
/*arguments maps and reduces*/ Job Counters Launched map tasks=2 Launched reduce tasks=1 /*arguments inputLines, maps and reduces, and average time*/ DataLines Maps Reduces AvgTime (milliseconds) 1 2 1 28846
Average time to finish the job was almost 29 seconds.
Test 2: 10 runs, default values
yarn jar /usr/hdp/2.3.4.0-3485/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-tests.jar mrbench -numRuns 10
Output (with my comments):
/*numRuns is 10, the job is run 10 times, each job starts with a counter. Example of job number to here. */ 16/06/21 13:06:42 INFO mapred.MRBench: Running job 1 DataLines Maps Reduces AvgTime (milliseconds) 1 2 1 20986
Average time per job was almost 21 seconds.
Test with results
Here is an example of one benchmark test.
yarn jar /usr/hdp/2.3.4.0-3485/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-tests.jar mrbench -numRuns 2 -maps 50 -reduces 10 -inputLines 100000000 -inputType random
Some results from running this test on one of my clusters.
| Input parameters | Output statistics | |||||
| inputLines | maps | reduces | numRuns | inputType | Input file size generated | Avg time |
| 1.000.000 | 10 | 5 | 2 | asc/desc | 7.4MB | 26s |
| 1.000.000 | 10 | 5 | 2 | random | 19.4MB | 28s |
| 10.000.000 | 10 | 5 | 2 | asc/desc | 85.8MB | 36s |
| 10.000.000 | 10 | 5 | 2 | random | 194.4MB | 35s |
| 100.000.000 | 10 | 5 | 2 | asc/desc | 256MB | 97s |
| 100.000.000 | 10 | 5 | 2 | random | 1.9GB | 100s |
| 100.000.000 | 50 | 10 | 2 | random | 1.9GB | 78s |
For measuring I/O (read/write) performance, check the post about TestDFSIO.





 Enter a password and save the changes.
Enter a password and save the changes.



 Save and Test the connection.
Save and Test the connection.



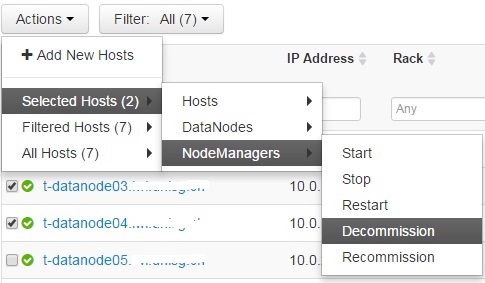
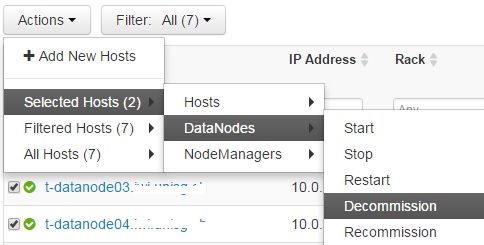

 Repeat this for every Datanode.Click OK on the confirmation window.
Repeat this for every Datanode.Click OK on the confirmation window.



{kind=link}